





.png)

Most organizations receive chunks of information. Some come from the customer service, some from their IT department and some from their market research team. This information might be random, anything from having a person’s name to his bill details. This random sets of information can start to make sense if organizations can organize this information correctly.
Companies can do well to interlink data that are similar – to be able to strategize better and understand their customers in a better way – a thing we commonly refer to as Big data.
What are we talking about, what is BIG data?
Organizations store data under different heads. Some relate to customer details, some relate to customer mail ID, and some relate to customer needs. Every bit of data is important, but it is useless until it is organized, processed and reduced to simpler forms so to make a sense out of it.
This data can be in the form of text, images, audio, videos – anything imaginable. Most of it would not make sense individually. However, put together in a certain way, they offer useful insights that can offer a detailed knowledge about the observed aspect. Combine your customers birth date with his personal taste and you might just understand how you can help him more with your products or services.
The term BIG DATA refers to large sets of data that are enormously large to be processed by the conventional methods of sorting and thus requires a smarter system to analyze, collect, share, store and simplify.
A system needs to process this data. It is this need that brought up the development of Relational Database Management systems and Hadoop and MongoDB – two big names in the Big Data market.
Talking about Hadoop
Hadoop is a Java-based open source software, developed by the Apache Software foundation in 2011. It is designed to store and process a large amount of data sets on computer clusters.
It consists of HDFS (Hadoop distributed file system), the storage part and the MapReduce, the processing part. The HDFS splits large data blocks into the nodes of the cluster, and this received data is processed parallelly through the package code that manipulates the data so to work efficiently and carry the process.
The data is acquired from the various sources, and these data bits are then passed to a system program that allocates locations to each data bit. These data bits carry this indexed data and move forward in the line to the processing unit. Here the data is harvested and is redirected to the intended nodes that carry the data to different locations to be stored. The program is equipped with the feature to prevent data loose, and machine failure, and so multiple copies of this data is produced and stored at different locations. The data transfer takes place through some reserved protocols and lines so to ensure security and prevent data corruption.
Networks like Facebook, Yahoo, Amazon use these cluster networks for data accumulation.
MongoDB brings solution to the data management hazard
MongoDb also called the NOSQL database, is a cross-platform database management system. Released in 2009 by the MongoDB Inc, this platform has made integration of data much simpler and faster. This is a free and open source software.
This software works as the back-end for many applications. This is among the popular NOSQL database management systems and enterprises like eBay, Craigslist and Viacom use this software for their services.
It utilizes document-oriented approach for data management. This means instead of creating copies of the data and saving it in a different location; this software stores the data in minimum space and least number of documents. Related documents like salary, employee id, and expenses for an enterprise would be compiled into a single document file, and this will not only make data easily available but also easy to manage records. Multiple copies of this compilation are produced to maintain a backup. Also, the read and write operations are initially performed on the primary copies, and the secondary copies remain unaffected until the temporary commands are made permanent. Thus, it can be concluded that the secondary replicas or the document are the read-only type.
Hadoop or MongoDB: A choice too difficult to make?
Both the platforms work on contradicting approaches. Hadoop works on the concept of distributing the data and creating multiple copies while MongoDB defines its algorithm by compiling all the related data into a single document.
Hadoop is designed to function in sync with the presently existing DBMS, while MongoDB is a replacement to these traditional programs.
Hadoop is itself a compilation of several software components while MongoDB is a DBMS in itself.
Can these offer a combined solution?
The MongoDB can help organize and accumulate enormous amounts of data. But this is not it, almost every application of the Big Data Management requires this data to be processed. Now the question that arises is can Hadoop provide this service. It is a good idea to work on but practically achieving this is a difficult task.
Hadoop uses languages like Pig and Hive, which compile as the MapReduce, and using this with the MongoDB is might solve the problem, and this is because the Mongo supports the native MapReduce language.
Working on a data as a whole and bulk processing exerts an excessive load on the hardware but if the load is distributed and the processing is different networks, the transaction takes place more efficiently and quickly.
The CAP (or Bower) theorem states that ‘distributed computing cannot achieve simultaneous Consistency, Availability, and Partition Tolerance while processing data.’ According to this concept, any system can achieve two out of the three above specified goals. This means that it is not possible to solve the problem entirely using a single software.
Some statistics of the platforms using these programs
The following table provides examples of customers using MongoDB together with Hadoop to power big data applications.
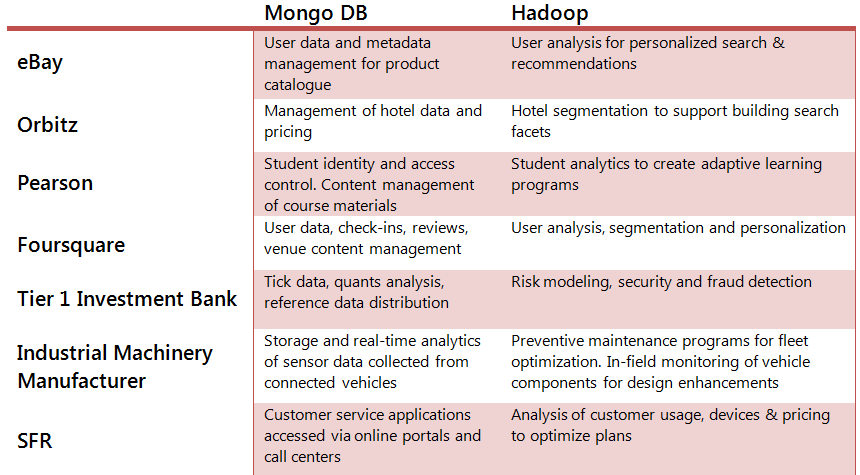
Source – mongodb.com
What should you look for?
Surveys and studies state that information generation would become two fold from within the next decade. One system alone would not be capable enough to process such enormous loads. If your organization is large, you need to depend on programs like Hadoop and Mongo together to handle and process data at such a large scale.

Written by Tanya Kumari
Tanya leads the Digital Marketing Team at Classic Informatics, a leading web development company . She is an avid reader, music lover and a technology enthusiast who likes to be up to date with all the latest advancements happening in the techno world. When she is not working on her latest article on agile team dynamics, you can find her by the coffee machine, briefing co-workers on the perks of living a healthy lifestyle and how to achieve it.








